Wakemate
About three weeks ago I finally received my Wakemate. A part of the burgeoning quantified self movement and yet another example of a product made possible by the last half-decade’s debut of cheap silicon accelerometers, it’s exactly the kind of thing you’d expect me to buy.
Wakemate is built on three ideas borrowed from sleep research. First: we experience a recurring cycle of sleep states during a night’s rest. Pretty much everyone’s aware of this, if only because it was part of an episode of Star Trek. Over the course of a night you spend progressively less time in a deep sleep state, and more in light states where dreaming occurs.
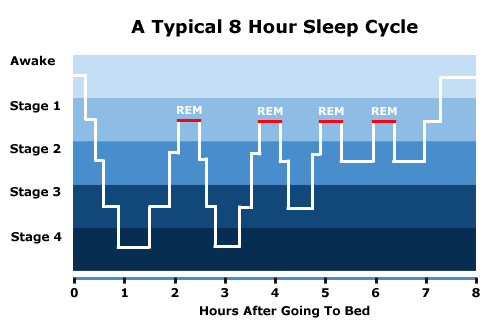
Second: these sleep states are measurable using a technique called actigraphy. As this paper explains, during sleep the motion of your non-dominant wrist seems to correlate pretty well with more precise measures of sleep state. You can get a decent measurement of sleep state just by tracking what your left hand is up to.
Third: your level of grogginess upon waking varies depending on which part of your sleep cycle you’re in when your alarm goes off. This is known as sleep inertia, and the WM’s creators have a few paper excerpts about it here.
The Wakemate folks took these three ideas and combined them — in a way sure to elicit much (potentially justified) tongue-clucking from sleep researchers — into a product. Put on a wristband, load a program on your phone, and set a twenty-minute window during which you’d like to wake up. The device keeps watch during that time period for moments when you seem to be in a light sleep state, doing its best to find one and rouse you in a way that minimizes grogginess (if it doesn’t find one, it’ll wake you up at the end of the time window). The idea’s so clever that I barely care whether it works.
Snakebit
I first heard about all of this from my colleague Kevin back in February of last year. It sounded like an interesting idea, and for just $5 you could reserve your place in line for the device (it ultimately cost me $50; it’s now selling for $60). Wakemate is a Y Combinator startup, and its founders went through a semi-hilarious series of problems as they tried to ship their first product. Bad wristbands. Delayed electronics. Problems with Apple certification. The thing finally arrived, months late; the next day I got an email warning me that the included power adapter might burn my house down. And for the first week or so, the app only woke me up at the end of the 20-minute window — at the fail-safe point — seemingly because it wasn’t able to communicate with the wristband (I had to reboot the latter unit multiple times to get the night’s data downloaded). With the exception of the charger (any USB adapter will do), all of these problems have been fixed. But it was a bumpy ride. Kevin still hasn’t received his.
Surprisingly Plausible
Here’s the source data from last Thursday’s sleep, and Wakemate’s classification of that data into sleep states.
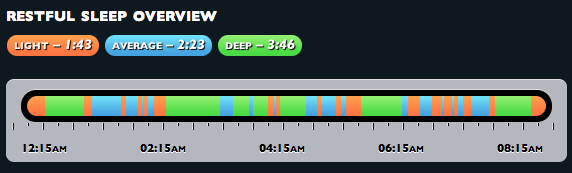
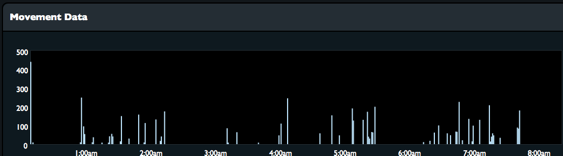
This seems kind of reasonable! Check out the huge spike at the beginning of the accelerometer time series. That’s when I was still awake and reading. Over the course of the night I went through about four cycles, spending less time in deep sleep each iteration. You can see four clusters of movement data, too. This isn’t the cleanest night’s worth of data — I didn’t feel like clicking through all of them to find the tidiest — but as I’ve looked at these over the past few weeks, I haven’t yet seen any patterns that seemed implausible either in terms of the reported sleep cycle pattern or its correlation to the underlying movement data.
Does It Work?
At first I was a bit disappointed: the central gimmick of the WM didn’t seem to be working. If anything, I seemed to be groggier than usual when I woke up. But as I already mentioned, I eventually realized that the alarm was only going off at the end of the twenty minute window. I emailed WM’s extremely responsive support line and was told that the issue had already been fixed in software and was just waiting on Apple certification. Happily enough, I was able to download the update by that evening. And although the days since have seen a suspicious number of wakings during the first minute of the alarm period, I’m actually surprised to report that it might be working. I’m still plenty groggy during the minute or two when I futz with the alarm (and report my level of alertness using the software slider). But I’ll be damned if I don’t seem to snap out of it sooner than usual.
On the other hand, this may not have anything to do with the timing of the alarm: it might just be that I’m getting more sleep. Which brings me to the best thing about Wakemate.
Data Porn
I was most excited for the alarm functionality, but the analytics package that WM provides has proven to be its most compelling feature. Your nightly sleep data is uploaded each morning and placed into an attractive interface. You can easily find information about time spent asleep, how long it took you to fall asleep, and how many times you woke up in the night. It’ll also show you how your recent performance in these areas compares to your career average, and to that of the entire population of WM users.
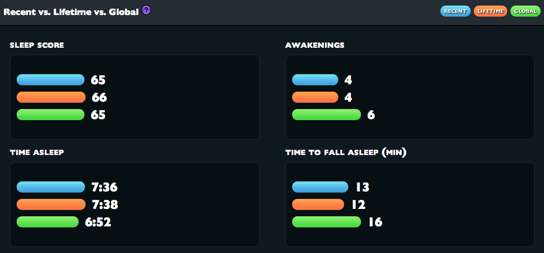
You can also tag each night’s sleep when you set the alarm — did you read before bed? go to the gym? drink alcohol? — and perform comparisons between tags.
Perhaps less helpfully, WM provides a “Sleep Score”. I can’t find any detailed information about how this is calculated — I suspect that this opacity is intentional, both to allow the formula to be tweaked and to keep users from trying to game it. And while it’s sort of amusing to have competitive sleeping leaderboards (how does Justin Sweetman sleep so virtuosically?), the scores seem to me to be basically bullshit. I tend to score highest when I’ve gone to bed late and with alcohol in my system; as you might guess, my scores don’t correlate very well with how rested I feel. You seem to be penalized for “low quality” sleep, even if it means more sleep — in other words, collapsing from exhaustion and sleeping like a corpse for three hours might earn you a higher sleep score than getting a normal night’s rest.
Since I’m on a bit of an Excel kick, here’s a plot of my sleep scores versus minutes asleep (WM recently added the ability to download your data as a CSV, which is nice of them).
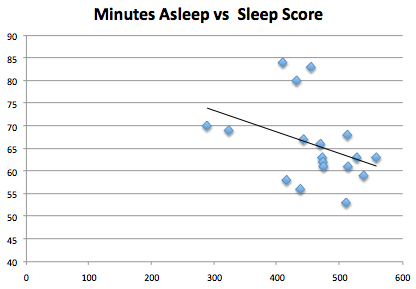
Admittedly, I don’t yet really have enough data for that trend line to be meaningful. But I have my suspicions.
Still, I’ve actually found the product to be worthwhile, not just as an interesting exercise in navel-gazing. For instance, it turns out there’s a reason my Sundays aren’t very productive:
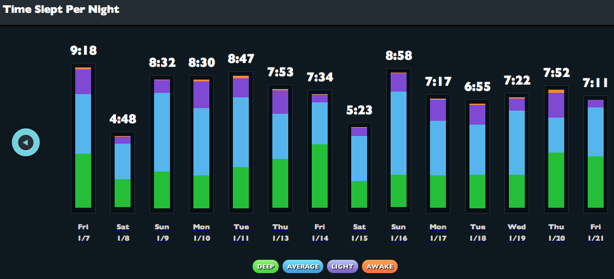
I honestly had no idea I was getting so little rest on weekends.
In general, I’d say that it’s been surprising and useful to have the amount of time I spend asleep quantified. I’ve always needed a relatively large amount of rest in order to function. I have nothing but admiration (and jealousy) for those of you who get five hours a night, hop out of bed, write a thousand words and run a half marathon. But I just can’t do it. At the absolute depths of puberty/hibernation my body, when left to its own devices, was helping itself to twelve or thirteen hours of sleep a night. That’s thankfully not necessary any more, but I’m certainly not at my best when I get less than eight hours.
Wakemate has actually been useful for telling me when I’m not taking very good care of myself, and has provided a small but real incentive for paying attention to when I should call it a night. Admittedly, you can see that incentive diminishing in the above graph as the novelty of the WM wears off. Still, I’ve found the information useful.
Anyway, if it sounds appealing, you might want to give it a try — although until I’m more convinced of the alarm’s utility, I’d suggest considering the FitBit as well. I haven’t tried FB, but in addition to sleep analysis it quantifies your activity during the day, which might be interesting. It hasn’t got any anti-sleep-inertia alarm functionality, but perhaps that’ll be added later.





{kind=link}